Slovarji & množice#
Ena najbolj uporabnih podatkovnih struktur v Pythonu so slovarji. Ti so tako kot seznami zbirka vrednosti, le da niso urejeni po zaporedoma oštevilčenih indeksih, temveč vsaka pripada ključu. Slovarje pišemo med zavite oklepaje, sestavljeni pa so iz parov kljuc: vrednost, ločenih z vejicami. Na primer: {'a': 1, 'b': 5, 'c': 10} ali {1: 'a', 5: 'b', 10: 'c'}. Ključi se ne smejo ponavljati, lahko pa različnim ključem pripada enaka vrednost. Vrednosti v slovarjih so poljubne, ključi pa so omejeni na nespremenljive vrednosti (na primer lahko so števila, nizi ali nabori, ne pa seznami). Kot smo že omenili, so slovarji zelo uporabni, zato začnimo z nekaj primeri uporabe.
Najočitnejša uporaba slovarjev so slovarji, ki besedam v enem jeziku priredijo njihove prevode:
slo_ang = {
'abak': 'abacus',
'abalienacija': 'abalienation',
'abderit': 'abderite',
...
'žvrkljati': 'whisk'
}
Seveda ni nujno, da nizem priredimo nize. Telefonski imenik je primer slovarja, ki nizem priredi številke:
nujne_telefonske_stevilke = {
'center za obveščanje': 112,
'policija': 113,
'informacije': 1188,
'točen čas': 195
}
Lahko pa tudi številkam priredimo nize:
rimske_stevilke = {
1: 'I', 2: 'II', 3: 'III', 4: 'IV',
5: 'V', 6: 'VI', 7: 'VII', 8: 'VIII',
9: 'IX', 10: 'X', 20: 'XX', 30: 'XXX',
40: 'XL', 50: 'L', 100: 'C', 500: 'D',
1000: 'M'
}
Slovarji se pogosto uporabljajo za predstavitev verjetnostih porazdelitev. Ključi so dogodki, pripadajoče vrednosti pa njihove verjetnosti:
met_kocke = {
1: 1/6, 2: 1/6, 3: 1/6,
4: 1/6, 5: 1/6, 6: 1/6
}
met_dveh_kock = {
2: 1/36, 3: 2/36, 4: 3/36, 5: 4/36,
6: 5/36, 7: 6/36, 8: 5/36, 9: 4/36,
10: 3/36, 11: 2/36, 12: 1/36
}
Predstavljamo pa lahko tudi bolj zapletene strukture. Na primer, oglejmo si sledečo matriko:
matrika = [
[1, 1, 4, 1, 1, 1, 1, 1, 1, 1],
[5, 2, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 3, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 4, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]
Vidimo, da je razen na nekaj mestih povsod enaka 1. Takim matrikam pravimo redke in v računalništvu se pogosto pojavljajo. Veliko bolj učinkovito jih predstavimo z njihovo dimenzijo, najpogostejšim elementom ter izjemami. Ker gre za različne vrste podatkov jih bomo predstavili z naborom (st_vrstic, st_stolpcev, element, izjeme), izjeme pa bomo predstavili s slovarjem, kjer bodo ključi mesta (stolpec, vrstica) v matriki, vrednosti pa elementi na teh mestih. Na primer, zgornjo matriko bi lahko na bolj učinkovit način predstavili kot:
redka_matrika = (6, 10, 1, {
(0, 2): 4,
(1, 0): 5,
(1, 1): 2,
(2, 4): 3,
(4, 2): 4
})
Tudi omrežja lahko predstavimo s slovarji. Ključi so vozlišča, vrednosti pa povezave iz teh vozlišč, torej zopet slovarji, ki imajo za ključe ciljna vozlišča, za vrednosti pa razdalje. Na primer, slovenski avtocestni križ, ki je videti kot
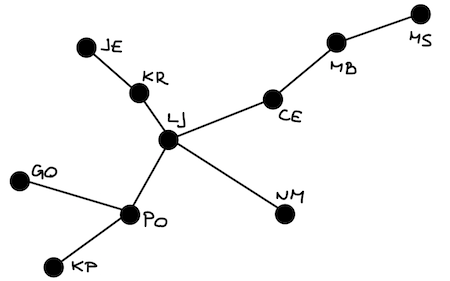
bi lahko predstavili s sledečim slovarjem:
avtocestni_kriz = {
'LJ': {'KR': 26, 'CE': 73, 'PO': 51, 'NM': 72},
'KR': {'LJ': 26, 'JE': 35},
'JE': {'KR': 35},
'CE': {'MB': 54, 'LJ': 73},
'MB': {'CE': 54, 'MS': 60},
'MS': {'MB': 60},
'PO': {'LJ': 51, 'KP': 64, 'GO': 63},
'GO': {'PO': 63},
'KP': {'PO': 64},
'NM': {'LJ': 72}
}
Osnovne operacije na slovarjih#
Slovarji podpirajo precej že poznanih osnovnih operacij. Z len dobimo velikost slovarja, torej število parov:
len({'a': 6, 'b': 2, 'c': 3})
3
Pozorni moramo biti, da operacije v osnovi delujejo na ključih slovarja:
max({1: 10, 2: 20, 3: 30})
3
3 in {1: 3, 2: 3, 4: 3}
False
Do posameznih vrednosti dostopamo tako kot pri seznamih, le da namesto indeksa podamo ključ (zaradi česar rezine ne pridejo v poštev):
s = {'a': 6, 'b': 2, 'c': 3}
s['b']
2
Če ključa v slovarju ni, dobimo napako:
s['d']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[6], line 1
----> 1 s['d']
KeyError: 'd'
Tako kot sezname, lahko tudi slovarje spreminjamo:
slovar = {'a': 10, 'b': 20}
slovar['a'] = 50
slovar
{'a': 50, 'b': 20}
V slovarje nove elemente dodajamo tako, da jih priredimo ustreznemu ključu:
slovar['c'] = 100
slovar
{'a': 50, 'b': 20, 'c': 100}
Elemente lahko pobrišemo z ukazom del:
del slovar['a']
slovar
{'b': 20, 'c': 100}
Vgrajene metode na slovarjih#
Seveda tudi na slovarjih obstaja kup uporabnih metod, ki so vse naštete v uradni dokumentaciji. Ena najuporabnejših je get, ki poskuša dobiti ključu pripadajočo vrednost, vendar ne javi napake, kadar ključa v slovarju ni, temveč vrne None.
slovar = {'a': 6, 'b': 2, 'c': 3}
slovar.get('a')
6
slovar.get('d')
Če želimo, lahko podamo še neobvezni argument, ki pove privzeto vrednost, ki naj se vrne, če ključa ni v slovarju:
slovar.get('d', 0)
0
Recimo, da želimo prešteti pojavitve znakov v nizu. Imejmo slovar, ki znakom priredi število njihovih pojavitev ter naredimo sprehod po nizu. Na sprehodu za vsak znak, ki ga srečamo, število pojavitev ustrezno povečamo:
def prestej_pojavitve(niz):
pojavitve = {}
for znak in niz:
if znak in pojavitve:
pojavitve[znak] += 1
else:
pojavitve[znak] = 1
return pojavitve
prestej_pojavitve('abrakadabra')
{'a': 5, 'b': 2, 'r': 2, 'k': 1, 'd': 1}
Če želimo, lahko namesto pogojnega stavka uporabimo tudi metodo get:
def prestej_pojavitve(niz):
pojavitve = {}
for znak in niz:
pojavitve[znak] = pojavitve.get(znak, 0) + 1
return pojavitve
prestej_pojavitve('abrakadabra')
{'a': 5, 'b': 2, 'r': 2, 'k': 1, 'd': 1}
Tako kot pri seznamih imamo na voljo pop, ki pa ji moramo podati ključ, ki ga želimo odstraniti iz slovarja (saj slovar ni urejen po vrsti, zato nima zadnjega elementa). Metoda ključ odstrani, pripadajočo vrednost pa vrne:
slovar = {'a': 10, 'b': 20}
slovar.pop('a')
10
slovar
{'b': 20}
Če res ne vemo, kateri ključ bi odstranili, lahko z metodo popitem odstranimo naključni par:
slovar = {'a': 10, 'b': 20}
slovar.popitem()
('b', 20)
slovar.popitem()
('a', 10)
slovar
{}
Zanke na slovarjih#
Tudi na slovarjih obstaja zanka for, ki pa se sprehaja po ključih slovarja.
for x in {'a': 1, 'b': 2, 'c': 3}:
print(x)
a
b
c
V novejših različicah Pythona zanka vrača ključe v takem vrstnem redu, kot smo jih dodajali v slovar, v starejših različicah pa naključno, zato bodite previdni, preden se zanašate na vrstni red.
Če želite dostopati do vrednosti slovarja, uporabite metodo values:
for x in {'a': 1, 'b': 2, 'c': 3}.values():
print(x)
1
2
3
Z metodo items pa lahko dostopate tudi do obojega hkrati:
for x in {'a': 1, 'b': 2, 'c': 3}.items():
print(x)
('a', 1)
('b', 2)
('c', 3)
Tako kot smo navajeni od funkcij enumerate in zip, lahko pare sproti razstavljamo:
for k, v in {'a': 1, 'b': 2, 'c': 3}.items():
print(k, '->', v)
a -> 1
b -> 2
c -> 3
Za vajo napišimo program, ki izračuna največjo vrednost v slovarju ter njen pripadajoči ključ. Ideja je podobna kot pri seznamih: po vrsti gledamo vse pare ključev in vrednosti v slovarju. Vsakič, ko vidimo še večjo vrednost, si zapomnimo njen ključ. Ker slovarji niso urejeni po vrsti, ne moremo začeti s prvim elementom, lahko pa si pomagamo z metodo popitem.
def najvecja_vrednost(s):
max_k, max_v = s.popitem()
for k, v in s.items():
if v > max_v:
max_k, max_v = k, v
return max_k, max_v
najvecja_vrednost(s)
('a', 6)
Funkcija ima pomanjkljivost, da pokvari vhodni seznam. Jo znate napisati tako, da ga pusti pri miru?
Tako kot sezname, lahko tudi slovarje na eleganten način sestavljamo z izpeljanimi slovarji. Na primer, namesto
potence_dve = {}
for i in range(10):
potence_dve[i] = 2 ** i
potence_dve
{0: 1, 1: 2, 2: 4, 3: 8, 4: 16, 5: 32, 6: 64, 7: 128, 8: 256, 9: 512}
lahko pišemo tudi:
{i: 2 ** i for i in range(10)}
{0: 1, 1: 2, 2: 4, 3: 8, 4: 16, 5: 32, 6: 64, 7: 128, 8: 256, 9: 512}
Izpeljane slovarje lahko tudi gnezdimo in omejimo s pogoji.
Množice#
S slovarji so v Pythonu tesno povezane tudi množice. Vrednosti v množicah pišemo med zavitimi oklepaji ter ločimo z vejicami, na primer {1, 5, 10}. Edina izjema je prazna množica, ki jo pišemo kot set(), saj {} predstavlja že prazen slovar.
Množice uporabljamo, kadar želimo (tako kot pri seznamih) delati s homogeno zbirko podatkov, le da nas ne zanima število ponovitev ter vrstni red. Ker se vsak element v njih pojavi enkrat, vrstni red pa je poljuben, so množice v resnici slovarji, pri katerih gledamo le na ključe, na pripadajoče vrednosti pa ne. Na tak način so množice tudi implementirane.
[1, 2, 3] == [2, 1, 3]
False
{1, 2, 3} == {2, 1, 3}
True
[1, 2, 3] == [1, 1, 2, 3]
False
{1, 2, 3} == {1, 1, 2, 3}
True
Na množicah so osnovne operacije unija, presek in razlika, ki jih pišemo kot:
{1, 2, 3, 4} | {3, 4, 5, 6}
{1, 2, 3, 4, 5, 6}
{1, 2, 3, 4} & {3, 4, 5, 6}
{3, 4}
{1, 2, 3, 4} - {3, 4, 5, 6}
{1, 2}
Seveda množice ne bi bile množice, če ne bi mogli preverjati vsebovanosti elementov:
1 in {1, 2, 3, 4}
True
2 in set()
False
Funkcija len nam vrne velikost množice:
len({1, 2, 3, 2, 1, 2, 3, 2, 1})
3
Zanka for se predvidljivo sprehaja po vseh elementih množice. Vrstni red, v katerem se sprehajamo, pa je malo manj predvidljiv:
for x in {'a', 'b', 'c'}:
print(x)
c
a
b
Množice lahko tudi spreminjamo. Elemente dodajamo z metodo add, ki deluje podobno kot append na seznamih:
mn = {1, 2, 3}
mn.add(4)
mn
{1, 2, 3, 4}
Na primer, direktno sliko funkcije f na množici bi lahko definirali kot:
def direktna_slika(f, a):
slika = set()
for x in a:
slika.add(f(x))
return slika
direktna_slika(abs, {1, -3, 2, -5, 10})
{1, 2, 3, 5, 10}
Enako bi lahko dosegli tudi z izpeljano množico:
def direktna_slika(f, a):
return {f(x) for x in a}
Elemente odstranjujemo z metodama remove in discard. Razlika med njima je, da prva javi napako, če elementa ni v množici.
mn = {10, 20, 30, 40}
mn.remove(20)
mn
{10, 30, 40}
mn.remove(50)
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[55], line 1
----> 1 mn.remove(50)
KeyError: 50
mn = {10, 20, 30, 40}
mn.discard(20)
mn
{10, 30, 40}
mn.discard(50)
mn
{10, 30, 40}
Metoda pop odstrani in vrne naključni element množice:
mn = {10, 20, 30}
mn.pop()
10
mn
{20, 30}
mn.pop()
20
mn
{30}
Če želimo dodati več elementov, lahko uporabimo metodo update, ki deluje tako, kot extend na seznamih.
mn = {10, 20, 30}
mn.update([40, 50])
mn
{10, 20, 30, 40, 50}
Množico lahko spreminjamo tudi z operacijami |=, &= in -=, ki obstoječo množico povozijo z unijo, presekom in razliko.
mn = {10, 20, 30}
mn |= {40, 50}
mn
{10, 20, 30, 40, 50}
mn = {10, 20, 30, 40}
mn &= {30, 40, 50}
mn
{30, 40}
mn = {10, 20, 30, 40}
mn -= {30, 40, 50}
mn
{10, 20}
Tako kot pri spreminjanju seznamov, je treba biti previden tudi pri spreminjanju množic (no, in tudi slovarjev). Na primer, ali spodnja programa delujeta enako?
mn = mn & {10, 20, 30, 40}
mn &= {10, 20, 30, 40}
Videti je, da je drugi le okrajšava za prvega, vendar ni res. Prvi izračuna presek ter dobljeno množico shrani pod imenom mn. Drugi ukaz pa spremeni množico, na katero kaže mn. Razliko lahko vidimo, če se na isto množico skličemo še pod drugim imenom:
mn = {1, 2, 5, 10, 20, 25}
mn2 = mn
mn = mn & {10, 20, 30, 40}
mn
{10, 20}
mn2
{1, 2, 5, 10, 20, 25}
Tako mn kot mn2 sta na začetku kazala na množico s šestimi elementi. Nato smo izračunali presek ter ga shranili pod ime mn, vendar je mn2 še vedno kazal na isto množico. Sedaj pa isto ponovimo še z &=:
mn = {1, 2, 5, 10, 20, 25}
mn2 = mn
mn &= {10, 20, 30, 40}
mn
{10, 20}
mn2
{10, 20}
Ukaz &= je spremenil množico, na katero je kazalo ime mn. Ker je na isto množico na začetku kazalo tudi ime mn2, zadnji klic pokaže presek.